
Reinforcement Learning with Human Feedback
ChatGPT has become widely used since its release. Built on GPT-3.5, a large language model (LLM), ChatGPT has the interesting ability to have conversations, unlike GPT-3.5 itself, which could only summarize or generate text from prompts. What made ChatGPT better is its ability to remember past instructions and conversations, this means it required less prompt engineering as it could understand conversations better.
Generative Pretrained Transformers (GPT), like BERT, RoBERTa, and other transformer models, are LLMs that generally predict the next token in a sequence, essentially learning a probability distribution of words. They have been shown to generate very human-like text. However, this can lead to a misalignment problem, where generated text is not aligned with what is intended by the user or is harmful.
Misalignment is a common term in AI and Machine Learning and it refers to the problem of a model not performing its intended task. In this case, the model may perform well on evaluations but fail to provide the desired solution. One example of misalignment could be a facial recognition system that has been trained on datasets that are not diverse or representative of the population it is intended to serve. This misalignment can result in inaccurate or biased facial recognition, which can have serious consequences.
To solve this issue, researchers have utilized Reinforcement among other methods. In reinforcement learning, the model learns through an action and reward system, where good behavior is rewarded, and bad behavior is discouraged. By incorporating RLHF, the model can learn which outputs of LLMs are favored by humans, enabling it to generate more appropriate tokens.
HOW?
In 2020, Stiennon et al. released “Learning to Summarise from Human Feedback”. In this paper, they aimed to solve the misalignment problem of LLMs in summarising posts by Reddit users.
Pretraining LLMs and fine-tuning on specific tasks using Supervised learning has become very common but these models still suffer from misalignment between their output and what the user wants. Since LLMs are trained with the objective of producing human-like text, there is still a problem because generated text although might be human-like, might not be exactly what the human wants. It could be that the generated text does not follow the user’s instructions (hallucinations), is wrong, or contains bias (racial, sexist, political, etc.).
While there are a couple of solutions to this problem, their paper suggests optimizing LLMs for quality. This means modifying the objective function to prioritize quality. This is achieved through Reinforcement Learning with Human Feedback. Here, a reinforcement learning agent is trained to generate text that is considered high-quality by humans. Reinforcement Learning trains an agent to perform a task by making it learn from its actions in an environment. The agent learns through an action-reward system, where there is a reward (positive or negative) for any action taken. In this case, the agent gets a positive or negative reward based on its output (generated text). Human evaluators help determine if the agent’s output is of high quality or not.
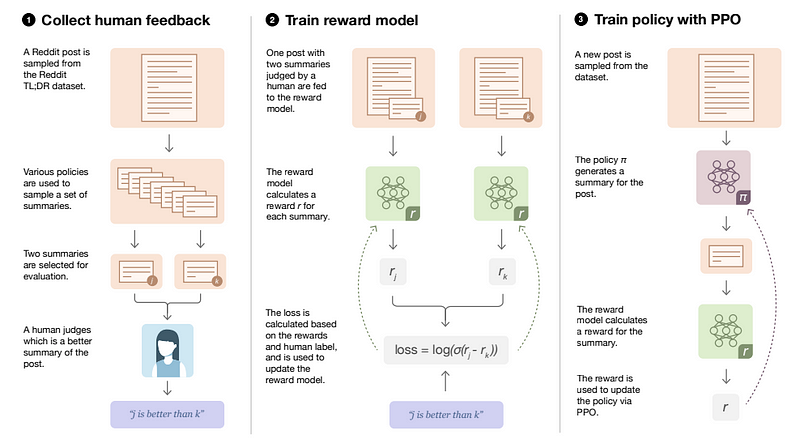
Diagram detailing how the RLHF model is trained from Stiennon et al.
For their work, Stiennon et al. used the TL;DR dataset that contains Reddit posts and their summaries. Training is done in 3 steps:
Starting with a supervised baseline, that is, a pretrained LLM fine-tuned via supervised learning on the TL;DR dataset. This baseline is used to produce summaries for the posts. Summaries from a given post are paired and given to human labelers who chose which of the two summaries they would consider to be better.
Using the data collected from the human labelers, a reward model is trained to output a scalar value (reward) when given a post and a generated summary. The reward model is also the fine-tuned LLM with the output layer replaced so the model outputs a scalar. The model uses a loss function that compares the quality of two summaries given a post.
Given a post x and summaries {y₀, y₁} and given that human picks a summary yᵢ as the better summary, then the loss is represented by
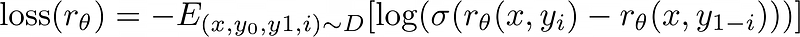
where,
- r(x, yi) is the predicted reward for summary yi given post x
- rθ(x, y1−i) is the predicted reward for the other summary y1−i given post x
- σ is the sigmoid function
- E(x,y0,y1, i)∼D represents taking the expectation over data D of all combinations of x, y0, y1, and i, where i is either 0 or 1 and specifies which summary is preferred by the human evaluator.”
The goal of the reward model is to get reward values for the generated summaries. The rewards are then used to train a reinforcement learning policy via Proximal Policy Optimization (PPO). The policy is an LLM fine-tuned for generating summaries and using PPO, it is optimized to generate better outputs as judged by humans. PPO updates the policy using the rewards as a signal. A value function is also required as it helps the agent estimates the expected return it will receive by following a policy. The authors of the paper used a transformer to estimate the PPO value function.
InstructGPT
Although no official paper was released on ChatGPT, OpenAI released a paper on InstructGPT which seems to be the foundation on which ChatGPT was built. This paper titled, “Training language models to follow instructions with human feedback” by Ouyang et al. uses the same strategy as Siennon et al. The paper was released back in march 2022, about nine months before ChatGPT was released to the public.
Unlike Siennon et al. that trained their model to generate better summaries, the goal here was to align users' prompt/instruction with the model’s output. So unlike the previous paper where the model was fine-tuned to summarise posts from Reddit, the goal here was to improve the model’s output across a variety of tasks while reducing its tendency to hallucinate, generate errors, and produce biased outputs.
The training process also consists of three steps as shown below.
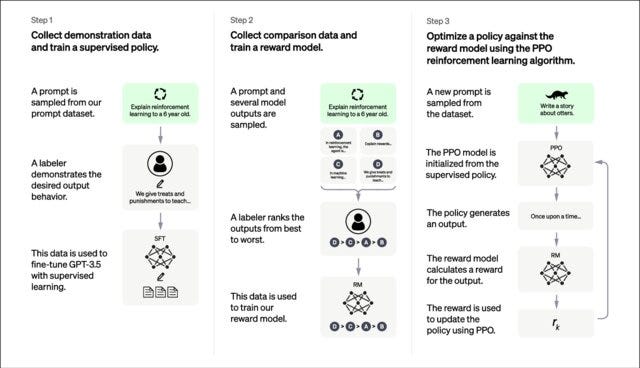
OpenAI training process for InstructGPT. From…
First, a prompt and response dataset collected by the researchers at OpenAI was used to fine-tune GPT-3.5 using supervised learning. This model is then used to generate a couple of responses when given prompts.
The supervised fine-tuned model (referred to as SFT in the paper) is also used as the reward model (RM) with the final output layers replaced with a linear head so the model outputs a single scalar value. But unlike before, where Siennon et al. compared only two outputs to see which of them was better, here between 4 to 9 outputs were compared for each prompt. So the labelers were asked to rank the outputs. They score each output based on its overall quality while also checking if it contains harmful or inappropriate content, among other things.

Labeler-collected Metadata from OpenAI API.
This new method changes the loss function a little. Previously, only one comparison is made per post, since only two outputs are generated. But here between four and nine outputs are generated for each prompt, therefore, to compare them in pairs would require between 6 and 66 comparisons. In general, given K outputs, `KC2` (K combination 2) comparisons would have to be made. The loss function for the reward model changes to

1/(KC2) is added to make sure all comparisons have the same impact on the loss.
The reward function is used to train a policy to generate better responses. The policy here is also a fine-tuned LLM and is trained using the PPO algorithm. This follows the same method used by Siennon et. al.
References
- Learning to Summarize from Human Feedback: Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano
- Training Language Models to follow instructions with Human Feedback: Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe
by sodipe🌚 on March 31, 2023